


Opened 4 years ago
Last modified 4 years ago
#3090 accepted enhancement
Modern implementation for Pearson R correlation and covariance
| Reported by: | bburlacu | Owned by: | bburlacu |
|---|---|---|---|
| Priority: | medium | Milestone: | HeuristicLab 3.3.x Backlog |
| Component: | Problems.DataAnalysis | Version: | trunk |
| Keywords: | Cc: |
Description
Our OnlinePearsonsRCalculator calculates the Pearson's R correlation coefficient from variance and covariance calculated by the OnlineMeanAndVarianceCalculator and the OnlineCovarianceCalculator using algorithms by Knuth (variance) and Welford (covariance).
Implementation-wise, OnlinePearsonsRCalculator class actually encapsulates three other calculator objects. With every pair of values, each of the three calculators performs basically the same checks on the input, leading to some inefficiency and more complicated and error-prone code.
We could instead be using an extension of Welford's algorithm by Schubert et al. [1] which computes everything (means, variances, covariances) in one pass, thus providing a simpler, numerically-stable, more performant implementation.
Attachments (1)
{kind=link}
Change History (4)
comment:1 Changed 4 years ago by bburlacu
- Status changed from new to accepted
comment:2 Changed 4 years ago by bburlacu
Changed 4 years ago by bburlacu
comment:3 Changed 4 years ago by bburlacu
Another possibility here:
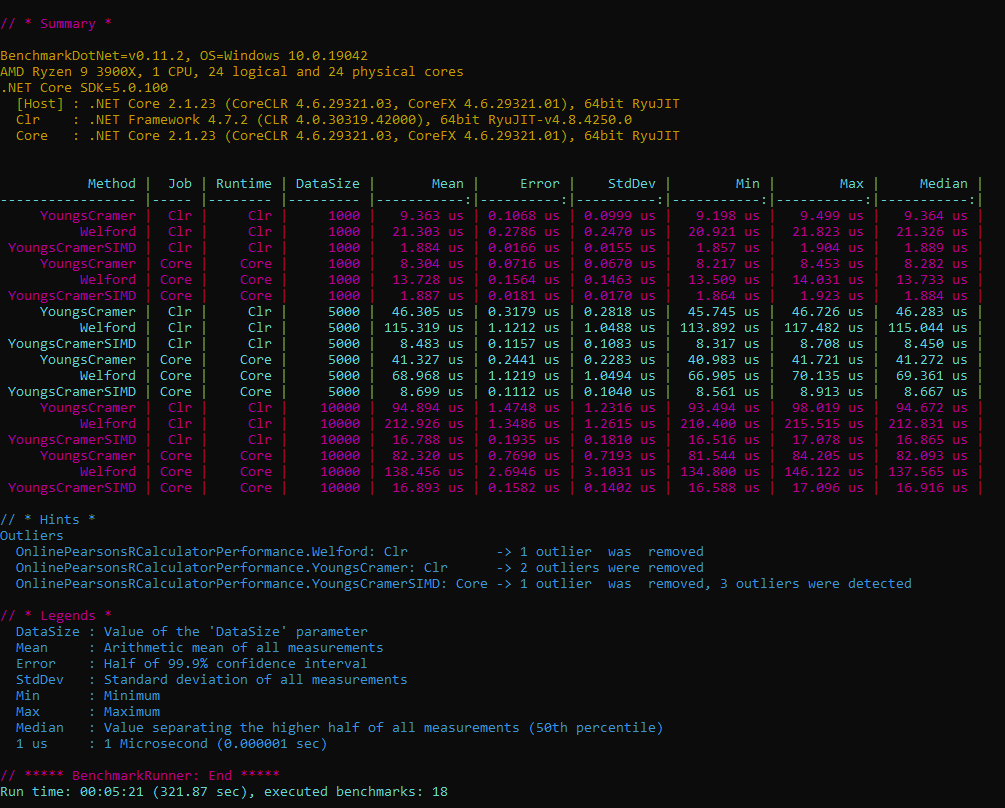
- use SIMD datatypes provided System.Numerics.Vector<double> (availabel as Nuget package) to implement a vectorized version of the R2 calculator (1) brings significant speedup.
- Between the two possible implementations (Welford algorithm vs Youngs-Cramer algorithm), use the latter as it is faster due to better pipelining (less heavy data dependency).

The image shows the difference between the current HL implementation (Welford) and the prototype SIMD-enabled Youngs-Cramer implementation. The speed-up is very significant
r17787: Implement extension to Welford's algorithm by Schubert et al in the OnlinePearsonsRCalculator.