


| Version 22 (modified by abeham, 10 years ago) (diff) |
|---|
How to ... use Hive for optimization
This page gives you instructions how to use HeuristicLab Hive for optimization problems.
Hive gives you the possibility to execute independent algorithms in parallel. It distributes those algorithms as jobs to a network of slaves which execute them and post back the results. Hive performs best if there is a large number of jobs which have long execution times. Also if limited memory is a issue on a local PC, Hive can be an advantage since it can decide to run the jobs only on machines with enough memory (like the blade server nodes).
The following steps are required to run a Hive Job with HeuristicLab 3.3.6 or above:
- Start HeuristicLab Optimizer
- Go to Services > Set Username / Password and enter your credentials
- You need a user and proper privileges as Hive User on the HEAL Hive server (which is services.heuristiclab.com). These privileges can be requested from S. Wagner if you are a research partner. If you are not a member of the HEAL research group or a research partner you can set up your own Hive server.
- Go to Services > Hive > Job Manager. Now the list of your Hive Jobs is updated. The jobs are grouped into the owners of the experiments.
- Click the plus symbol on top of the list to create a new Hive Job
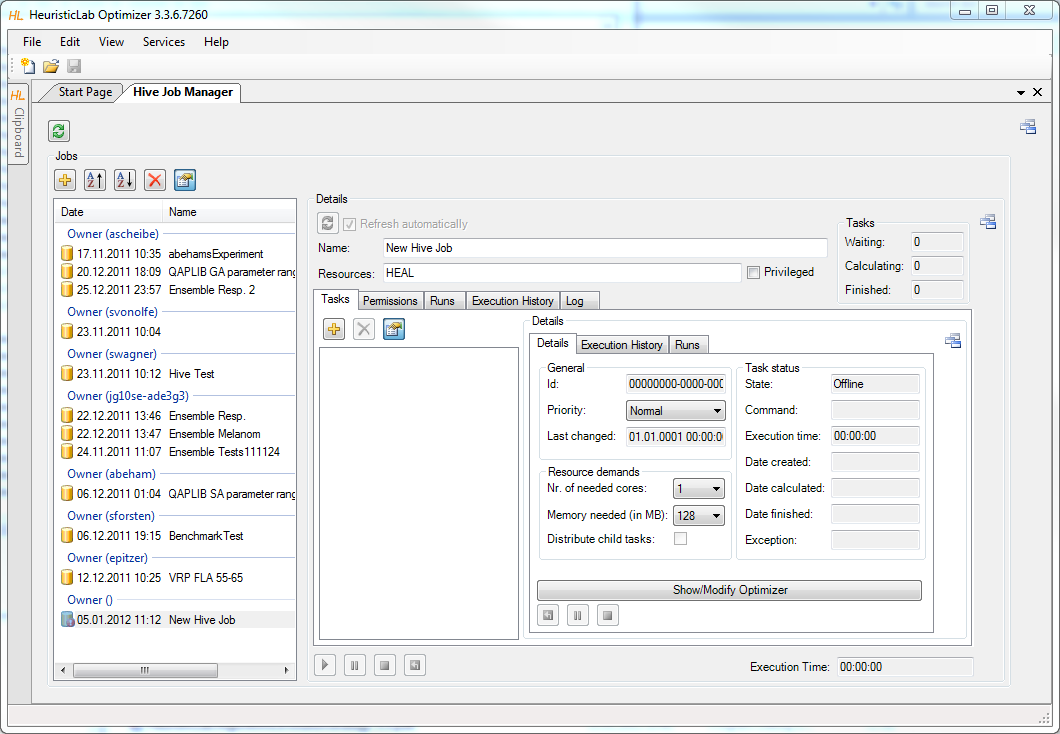
- Now you need to specify which job should be executed on the Hive. You can either
- ... create a new task by clicking the "plus symbol".
- ... move an existing experiment onto the view via drag and drop.
- After having created or loaded an experiment you can click "Modify Optimizer" in the details view to modify it.
- Each algorithm (also experiments and batch-runs) represent one task.

- Important configurations are:
- Nr. of needed cores: (default: 1) Specifies how many cores will be reserved for this job on the executing machine. If you know the algorithm corresponding to this job will use multiple threads for computation, increase this number!
- Memory needed: (default: 128) Specifies how much memory will be reserved for this job on the executing machine. It will only deployed on machines where the specified amount of memory is available.
- Priority: (default: Normal) The priority effects the scheduling of the tasks. There are 3 options available. Tasks with priority Critical get scheduled before tasks with priority Urgent and of course tasks with priority Urgent get scheduled before tasks with priority Normal. It is recommended to rank jobs with long execution-times to be executed earlier to avoid waiting for them in the end. Please use the Critical priority really only in case of emergency because this could lead to blocking the jobs of other users.
- Distribute child tasks: This flag is only available for experiments and batch-runs.
- Experiment: (default: true) If true, a task will be created for each child-optimizer. If false the whole experiment will be executed as one job.
- BatchRun: (default: false) If true, a number of tasks will be created corresponding to the number of repetitions specified. If false the batch-run will be executed as one task.
- There are also some configurations available for the whole job:
- ResourceIds: You can specify on which machines your jobs should be executed. Those machines/resources are grouped into resource-groups. The top group is "HEAL". You can either enter the name of a group or the name of a specific machine.
- Privileged: Tasks on Hive are executed in a secure sandboxed appdomain. However some plugins might require elevated privileges. If Privileged is checked, the tasks will be executed in a unrestricted appdomain. This option is only enabled if the user is allowed to (there is a role called "Hive IsAllowedPrivileged"). If you need this permission, please contact S. Wagner.
- After configuring the job you can hit "Start Job" and the job will be uploaded to the Hive. Hive will then take care of the distribution and execution of each task.
- While you keep the Hive Job Manager open, it will periodically fetch the status-updates of all tasks. When tasks are finished it will download the results automatically.
- You can also close HeuristicLab after uploading an Hive Job. When you open the Hive Job Manager again, it will download the list of your Hive Jobs and you can choose to download a specific one.
- Notice that when results are downloaded they will be reassembled into the original job. So after it finished you can again open the original algorithm/batch-run/experiment ("Open/Modify Optimizer") and see all the results in the RunCollection as if it would have been executed locally.
- Unfortunately it is not possible to preserve the ResultsCollection of each algorithm when reassembling the experiment. However each ResultsCollection is stored in the RunsCollection anyway.


Plugins
Hive automatically uses your local plugins. If they are not yet available on the server (because you are the first one to use this plugin), they are uploaded. When the tasks are executed, exactly those plugins are used.
Hive now also checks if you have modified a plugin. This means that you can modify plugins locally and use them in Hive, even though they have the same name and version as already existing plugins on the Hive server. To distinguish plugins, Hive uses checksums for comparing plugins and finding out if they are modified. If Hive notices that you have a modified assembly, it is automatically uploaded to the server.
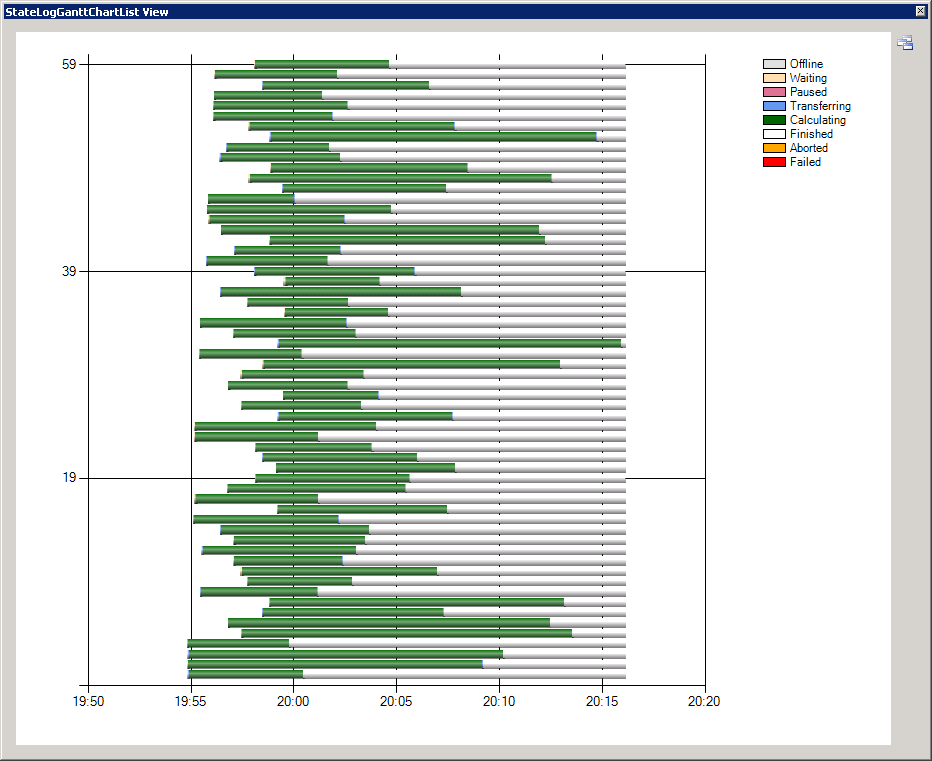
Job-States
You can observe the states of all jobs in the "States" tab. It shows a gantt-chart of your jobs. This is very helpful to get a quick overview of the runtimes of all jobs:

Job Sharing
Jobs can be shared with Full or Read permissions. To do so, go to the Sharing tab and hit refresh. You will see the list of already granted permissions (empty at first -- the owner always has full permissions). Click add and enter the username of who you want to share with as well as the desired permission. After saving the permission, the other user will see that job in his job-list. Permissions can only be added to jobs which are already uploaded. Permission include the following actions:
- Read: Download job, view tasks
- Full: Control job and tasks, delete job, grant permissions to other users

Statistics
To observe the current status and the workload there is a website which shows this information: http://services.heuristiclab.com/Hive-3.3/Status.aspx
Attachments (4)
- JobStates.png (37.8 KB) - added by cneumuel 13 years ago.
- Permissions.png (68.5 KB) - added by cneumuel 13 years ago.
- HiveExperiment.png (121.3 KB) - added by ascheibe 13 years ago.
- JobConfiguration.png (142.4 KB) - added by ascheibe 13 years ago.
{kind=link}
{kind=link}
Download all attachments as: .zip