


| Version 3 (modified by bburlacu, 12 years ago) (diff) |
|---|
Crossover Operators
All the GP1 crossover operators implemented in HeuristicLab take two parents (parent0 and parent1) and perform subtree swapping in place, returning the first parent as the crossover result. The runtime complexity of each crossover operator is expressed in terms of the number of tree evaluations (for those crossover algorithms that implement evaluation-based heuristics), but in reality performance is also dependent on problem size and quality measurement formula used.
1 Size-fair crossover
The size-fair crossover operator takes two parents and produces a single offspring, in a number of steps:
- It selects a crossover point (i.e., a node for crossover) from parent0
- It selects a compatible subtree in parent1 (subject to size limits and grammar constraints)
- It performs the swap and returns the (now different) parent0
The selection (step 2) above is influenced by a configurable bias towards internal or leaf nodes, given by the InternalCrossoverPointProbability parameter2.
2 Probabilistic functional crossover
This crossover is an implementation of the operator described by C. Bongard in [1] and denoted P-FXO (Probabilistic Functional Crossover). Bongard argues that crossover should be controlled in such a way that the original information in the genome would not be so greatly altered. Another argument behind Bongard's approach is that crossover is more likely to produce better offspring if based on the behavioral rather than structural similarity between nodes in the two parents (the so-called “benefic exchange of genetic information”). In order to avoid neutral crosses (that would have zero behavioral effect on the new trees), the procedure is made non-deterministic:
- A crossover point, corresponding to a node i is randomly chosen from parent0
- The behavioral distances between node i and every node j from parent1 are computed using a formula that takes into account the minimum and maximum values computed by the two nodes during evaluation:

- Once all the behavioral distances between node i and every node j have been calculated, they are normalized:
 and turned into selection probabilities (weights):
and turned into selection probabilities (weights):

- A node from the second parent is probabilistically chosen and swapped with node i from the first parent
This crossover has to evaluate one subtree from the first parent and n compatible subtrees from the second parent, giving it a runtime complexity of O(n).
3 Semantic similarity crossover
This crossover also follows up on the idea of beneficial exchanges of genetic material, based on a measure of “semantic similarity” as described by Nguyen, et al. in [3, 4].
- The sampling semantics of a subtree is defined as the collection of its evaluated values over a sequence of points from the dataset.
- The sampling semantic distance (SSD) between two nodes (subtrees) is defined as the absolute mean between their corresponding sampling semantics:

where S1 and S2 are the two subtrees, and U, V are their respective sampling semantics.
- Two nodes are deemed similar if their SSD falls within a predefined interval [alfa,beta]:

The crossover procedure chooses a crossover point from parent0, then picks the first node in parent1 that satisfies the similarity condition (5). As far as performance is concerned, we assume that parent1 has n subtrees that could be swapped into parent0:
- In the best case scenario the first subtree in parent1 will match the similarity condition, so the algorithm will only perform two computations of the sampling semantics, so it will return in constant time, the runtime complexity being .
- In the worst case scenario, the last subtree will match (or none), so the total number of sampling semantics computations will be n, resulting in O(n) complexity.
Therefore, on average, the runtime complexity in terms of the number of times the sampling semantics need to be computed will be O(n/2) (linear time).
4 Context-aware crossover
Given a randomly selected crossover point from parent1, context-aware crossover will always find the best location to place the subtree into parent0. Because of the initial random step, the context-aware crossover does guarantee that the resulting offspring will be better than its parents. It makes the best choice given a specific piece of genetic material. The complexity depends on the number of nodes in the first parent, since the algorithm will perform a swap followed by a tree evaluation for every available position, so that it can find out the best insertion point. This means n evaluations for n available positions, giving an O(n) complexity. A discussion of this crossover can be found in [2].
5 Deterministic-best crossover
As opposed to the context-aware crossover, where the insertion point is random and the initial genetic material available for swapping is fixed (the subtree chosen from the second parent), in the case of the deterministic-best crossover, the insertion point in parent0 is fixed, while the algorithm will find the best match from the available nodes in parent1. This also implies n swaps followed by n tree evaluations, with n being the number of available nodes in the second parent, therefore the complexity is also O(n).
6 Depth-constrained crossover
The depth-constrained crossover only acts within a specific depth range, in accordance with the DepthRange parameter that can take three values (for a tree of depth d)
- HighLevel (acting on the upper tree levels between )
- Standard (acting on the mid-area of the tree between depth levels )
- LowLevel (acting on the lower levels between )
References
[1] Bongard, Josh C., "A probabilistic functional crossover operator for genetic programming", in Proceedings of the 12th annual conference on Genetic and evolutionary computation (New York, NY, USA: ACM, 2010), pp. 925--932.
[2] Majeed, Hammad and Ryan, Conor, "Using context-aware crossover to improve the performance of GP", in Proceedings of the 8th annual conference on Genetic and evolutionary computation (New York, NY, USA: ACM, 2006), pp. 847--854.
[3] Uy, Nguyen Quang and O'Neill, Michael and Hoai, Nguyen Xuan and Mckay, Bob and Galván-López, Edgar, "Semantic similarity based crossover in GP: the case for real-valued function regression", in Proceedings of the 9th international conference on Artificial evolution (Berlin, Heidelberg: Springer-Verlag, 2010), pp. 170--181.
[4] Uy, Nguyen Quang and Hoai, Nguyen Xuan and O'Neill, Michael and McKay, Bob, "The role of syntactic and semantic locality of crossover in genetic programming", in Proceedings of the 11th international conference on Parallel problem solving from nature: Part II (Berlin, Heidelberg: Springer-Verlag, 2010), pp. 533--542.
Attachments (10)
-
71lyxpreview1.png
(2.9 KB) -
added by bburlacu 12 years ago.
01-behavioral-distance
-
72lyxpreview1.png
(2.5 KB) -
added by bburlacu 12 years ago.
02-normalized-behavioral-distance
-
73lyxpreview1.png
(2.9 KB) -
added by bburlacu 12 years ago.
03-behavioral-selection-weights
-
77lyxpreview1.png
(3.0 KB) -
added by bburlacu 12 years ago.
04-semantic-similarity-distance
-
83lyxpreview1.png
(4.2 KB) -
added by bburlacu 12 years ago.
05-semantic-similarity-condition
- 01-PFX-behavioral-distance.png (2.9 KB) - added by bburlacu 12 years ago.
- 02-PFX-normalized-behavioral-distance.png (2.5 KB) - added by bburlacu 12 years ago.
- 03-PFX-selection-probabilities.png (2.9 KB) - added by bburlacu 12 years ago.
- 04-SSX-sampling-semantic-distance.png (3.0 KB) - added by bburlacu 12 years ago.
- 05-SSX-similarity-condition.png (4.2 KB) - added by bburlacu 12 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
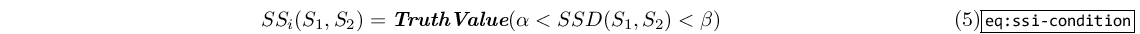{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
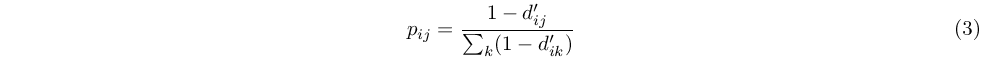{kind=link}
{kind=link}
{kind=link}
{kind=link}
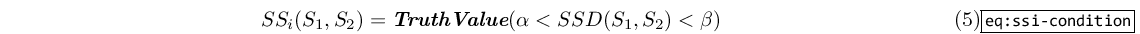{kind=link}
Download all attachments as: .zip