


How to ... use the HiveEngine
To use the HiveEngine you need the assemblies found in the Meta-Optimization branch. Just as explained in the using Hive howto you must enter your credentials before you can use it. When you start HL and open an algorithm you can choose the HiveEngine at the engines-tab.
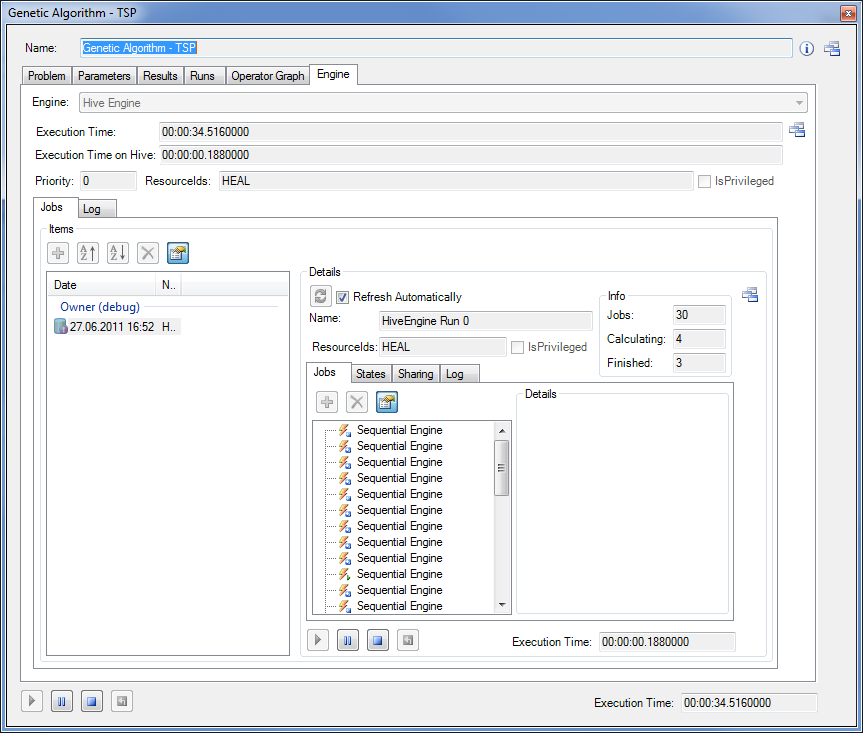
The HiveEngine parallelizes child-operations from UniformSubScopesProcessor-operations where the Parallel flag is set to true. The genetic algorithm for example is pre-configured to parallelize the solution evaluation of all individuals. If the HiveEngine is used for such a genetic algorithm every time a new UniformSubScopesProcessor-operator is executed (the solution evaluation) a new Hive Job is created:

A job is created for every child-operation (= one solution evaluation). The jobs are uploaded and executed in the Hive. When all jobs are finished the scopes of the resulting operations are copied back into the original operations and the algorithm continues. The HiveExperiment is deleted after it finished. The runtime-information about previous HiveEngine runs is still available after those HiveExperiments are deleted online. However they are not stored when the algorithm is stored. Every time a new UniformSubScopesProcessor-operator is executed this process repeats.

When the algorithm is paused or stopped, the current HiveEngine run is deleted. When resume is hit a new HiveEngine run is created, so pausing results in the loss of all currently calculating jobs.
Attachments (2)
- HiveEngine.png (67.4 KB) - added by cneumuel 13 years ago.
- HiveEngine2.png (66.9 KB) - added by cneumuel 13 years ago.
{kind=link}
{kind=link}
Download all attachments as: .zip