


HeuristicLab 3.3 Architecture
Software Model
HeuristicLab 3.3 builds upon a plugin architecture so that it can be extended without developers having to touch the original source code. Plugins are used as architectural paradigm and collaboration between plugins is described by interfaces (contracts).
Every HeuristicLab feature, even the Optimizer user interface, is available as a plugin. The plugin management mechanism contains a discovery service that can be used to retrieve all types implementing an interface required by the developer. It takes care of locating all installed plugins, scanning for types, and instantiating objects. As a result, building extensible applications is just as easy as dening appropriate interfaces (contracts) and using the discovery service to retrieve all objects fullfilling a contract.
Algorithm model
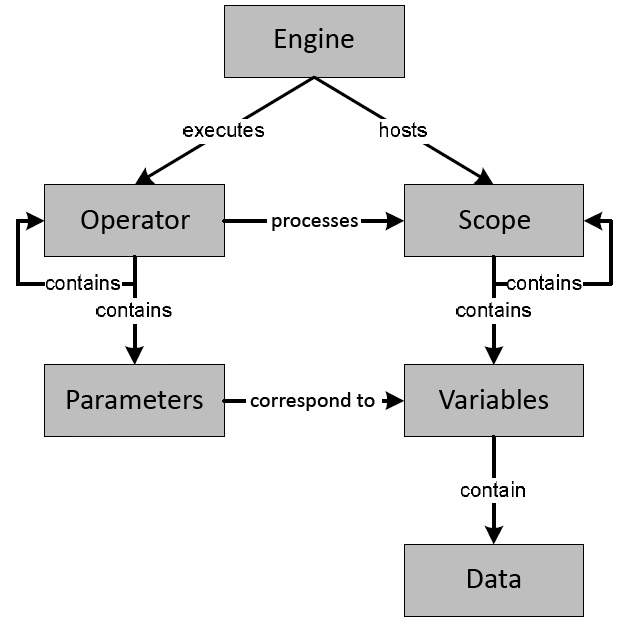
The core of HeuristicLab is its algorithm model. It is very easy to understand on an abstract level, but naturally reveals more complexity the deeper one descends into it. However, luckily for most users, understanding more than the abstract level of the core language is not necessary for applying heuristic optimization.

The algorithm model splits into three distinct models itself:
Data Model
In the data model each value is represented as a HeuristicLab 3.3 object that can be saved, restored and viewed. Standard data types such as integers, doubles, strings, or arrays that do not offer these properties are wrapped in HeuristicLab 3.3 objects. These values are linked to a name by storing them in a variable. The data type of a variable is not fixed explicitly but is given by the type of the contained value. In a typical heuristic optimization algorithm a lot of different data values and therefore variables are used. Hence, in addition to data values and variables, another kind of objects called scopes is required to store an arbitrary number of variables. To access a variable in a scope, the variable name is used as an identifer. Thus, a variable name has to be unique in each scope the variable is contained. Finally, these scopes can be hierarchically organized as trees. A scope may have several so-called sub-scopes, much like a metaheuristic population has many solutions which again might have several components.
Operator Model
The next part of the algorithm model considers the representation of single steps or statements in form of the operator model. Each algorithm is a sequence of clearly defined, unambiguous and executable instructions. In the HeuristicLab 3.3 algorithm model these atomic building blocks are called operators and are also represented as HeuristicLab 3.3 objects.
Operators have two main tasks. They
- are applied on scopes to access/manipulate variables and subscopes.
- define which operators are executed next.
Regarding the manipulation of variables, the approach used in the HeuristicLab 3.3 operator model is similar to formal and actual parameters of procedures. Each operator defines parameters for each variable it expects and possibly manipulates. By this means, operators are able to encapsulate functionality in an abstract way: A formal name is defined for a parameter which is used inside the operator. But after instantiating an concrete operator in the GUI and adding it to an algorithm at run time, the user defines the actual name of the parameter. The original code of the operator does not have to be modied. The implementation of the operator is decoupled from concrete variables and can be reused.
Execution Model
Algorithms are represented as operator graphs and executed step-by-step on virtual machines called engines. In each iteration an engine performs an operation, i.e., it applies an operator to a scope. As the execution order of an algorithm is dynamically defined by its operators, each operator may return one or more operations that have to be executed next. These pending operations are kept in a stack. In each iteration, an engine pops the next operation from the top of its stack, executes the operator on the scope, and pushes returned successor operations back on the stack.
Attachments (1)
-
core_architecture.jpg
(69.3 KB) -
added by mkofler 14 years ago.
HL core architecture
{kind=link}
Download all attachments as: .zip